Question
When trying to connect from PowerBI to ClickHouse using the connector, you receive the following authentication error:
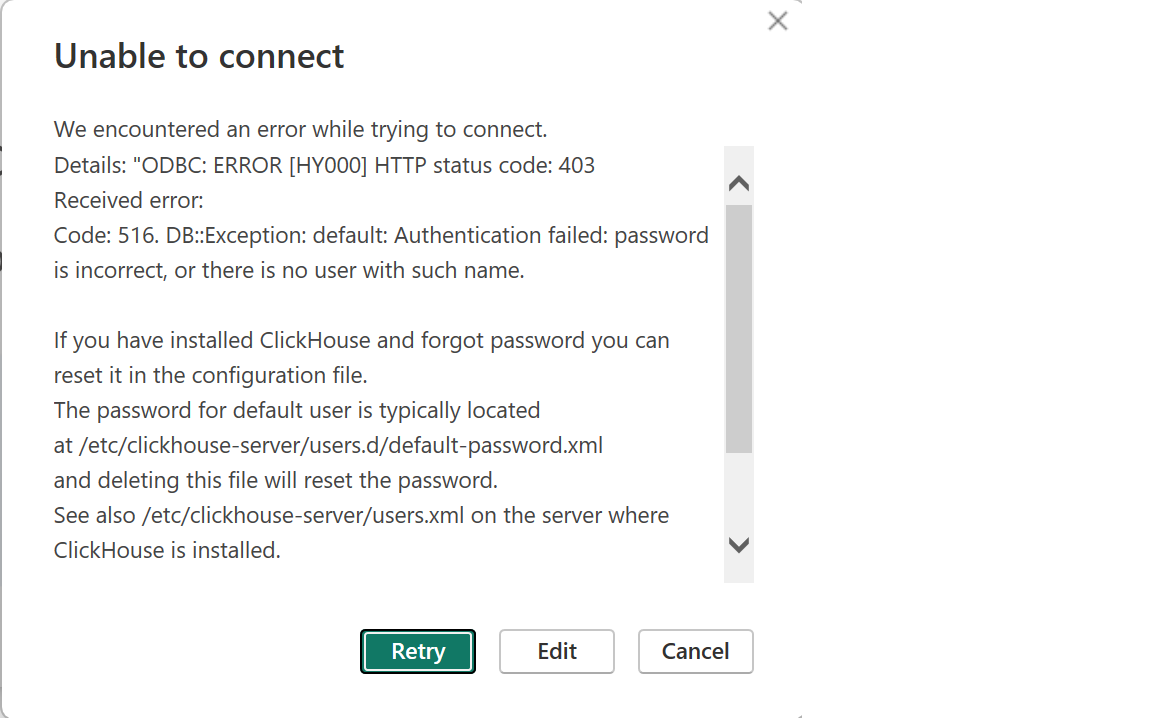
We encountered an error while trying to connect.
Details: "ODBC: ERROR [HY000] HTTP status code: 403
Received error:
Code: 516. DB::Exception: default: Authentication failed: password is incorrect, or there is no user with such name.
If you have installed ClickHouse and forgot password you can reset it in the configuration file.
The password for default user is typically located at /etc/clickhouse-server/users.d/default-password.xml and deleting this file will reset the password.
See also /etc/clickhouse-server/users.ml on the server where
ClickHouse is installed.
Answer
Check the password being used to see if the password contains a tilde ~.
The recommendation is to use a dedicated user for the connection and set the password manually. If using ClickHouse Cloud and the admin level of permissions with the default user is needed, then create a new user and and assign the default_role.
For more information:
https://clickhouse.com/docs/en/operations/access-rights#user-account-management
https://clickhouse.com/docs/en/cloud/security/cloud-access-management#database-roles