Schema Design
Understanding effective schema design is key to optimizing ClickHouse performance and includes choices that often involve trade-offs, with the optimal approach depending on the queries being served as well as factors such as data update frequency, latency requirements, and data volume. This guide provides an overview of schema design best practices and data modeling techniques for optimizing ClickHouse performance.
Stack Overflow dataset
For the examples in this guide, we use a subset of the Stack Overflow dataset. This contains every post, vote, user, comment and badge that has occurred on Stack Overflow from 2008 to Apr 2024. This data is available in Parquet using the schemas below under the S3 bucket s3://datasets-documentation/stackoverflow/parquet/:
The primary keys and relationships indicated are not enforced through constraints (Parquet is file not table format) and purely indicate how the data is related and the unique keys it possesses.
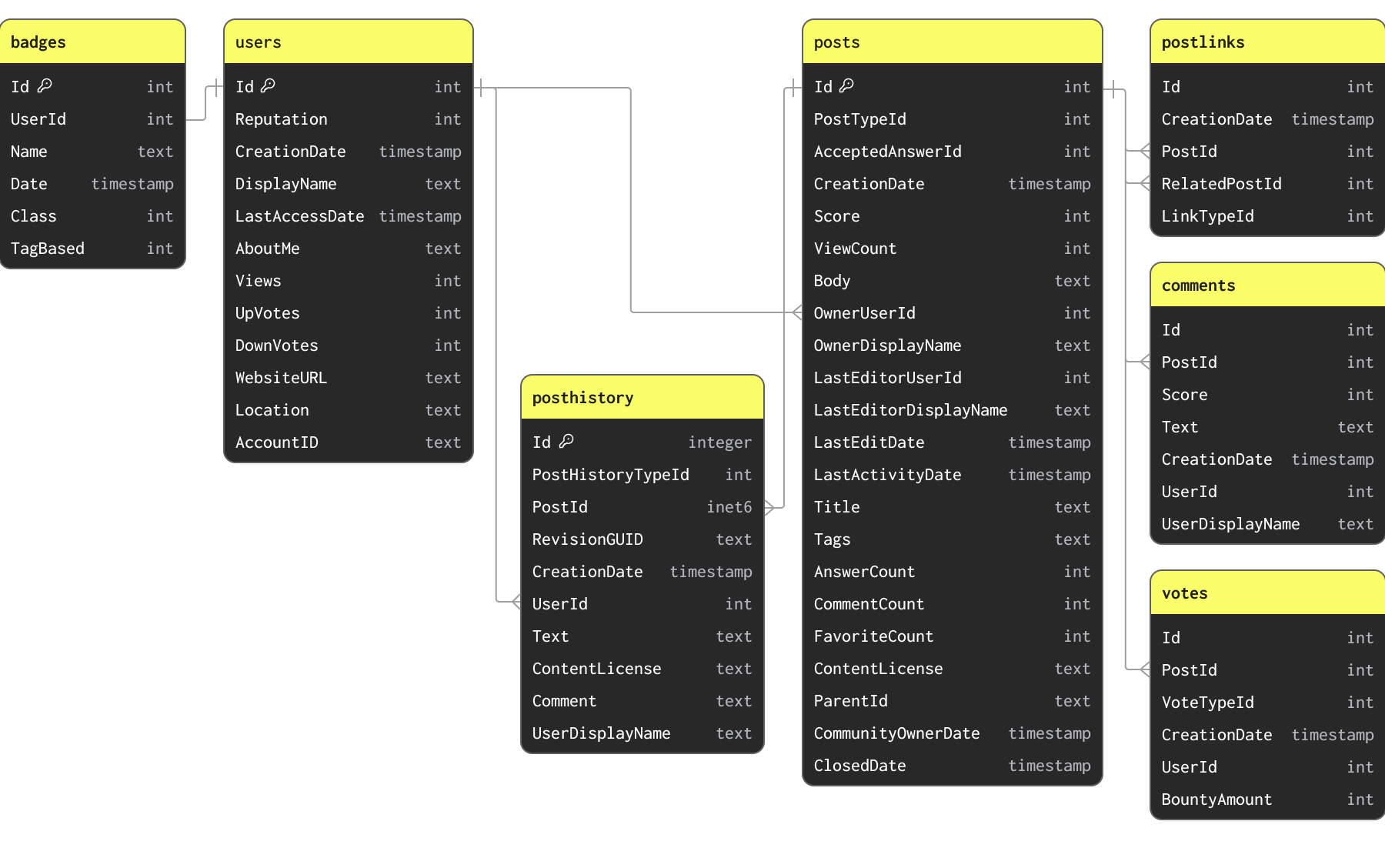
The Stack Overflow dataset contains a number of related tables. In any data modeling task, we recommend users focus on loading their primary table first. This may not necessarily be the largest table but rather the one on which you expect to receive most analytical queries. This will allow you to familiarize yourself with the main ClickHouse concepts and types, especially important if coming from a predominantly OLTP background. This table may require remodeling as additional tables are added to fully exploit ClickHouse features and obtain optimal performance.
The above schema is intentionally not optimal for the purposes of this guide.
Establish initial schema
Since the posts table will be the target for most analytics queries, we focus on establishing a schema for this table. This data is available in the public S3 bucket s3://datasets-documentation/stackoverflow/parquet/posts/*.parquet with a file per year.
Loading data from S3 in Parquet format represents the most common and preferred way to load data into ClickHouse. ClickHouse is optimized for processing Parquet and can potentially read and insert 10s of millions of rows from S3 per second.
ClickHouse provides a schema inference capability to automatically identify the types for a dataset. This is supported for all data formats, including Parquet. We can exploit this feature to identify the ClickHouse types for the data via s3 table function andDESCRIBE command. Note below we use the glob pattern *.parquet to read all files in the stackoverflow/parquet/posts folder.
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
SETTINGS describe_compact_output = 1
┌─name──────────────────┬─type───────────────────────────┐
│ Id │ Nullable(Int64) │
│ PostTypeId │ Nullable(Int64) │
│ AcceptedAnswerId │ Nullable(Int64) │
│ CreationDate │ Nullable(DateTime64(3, 'UTC')) │
│ Score │ Nullable(Int64) │
│ ViewCount │ Nullable(Int64) │
│ Body │ Nullable(String) │
│ OwnerUserId │ Nullable(Int64) │
│ OwnerDisplayName │ Nullable(String) │
│ LastEditorUserId │ Nullable(Int64) │
│ LastEditorDisplayName │ Nullable(String) │
│ LastEditDate │ Nullable(DateTime64(3, 'UTC')) │
│ LastActivityDate │ Nullable(DateTime64(3, 'UTC')) │
│ Title │ Nullable(String) │
│ Tags │ Nullable(String) │
│ AnswerCount │ Nullable(Int64) │
│ CommentCount │ Nullable(Int64) │
│ FavoriteCount │ Nullable(Int64) │
│ ContentLicense │ Nullable(String) │
│ ParentId │ Nullable(String) │
│ CommunityOwnedDate │ Nullable(DateTime64(3, 'UTC')) │
│ ClosedDate │ Nullable(DateTime64(3, 'UTC')) │
└───────────────────────┴────────────────────────────────┘
The s3 table function allows data in S3 to be queried in-place from ClickHouse. This function is compatible with all of the file formats ClickHouse supports.
This provides us with an initial non-optimized schema. By default, ClickHouse maps these to equivalent Nullable types. We can create a ClickHouse table using these types with a simple CREATE EMPTY AS SELECT command.
CREATE TABLE posts
ENGINE = MergeTree
ORDER BY () EMPTY AS
SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
A few important points:
Our posts table is empty after running this command. No data has been loaded. We have specified the MergeTree as our table engine. MergeTree is the most common ClickHouse table engine you will likely use. It's the multi-tool in your ClickHouse box, capable of handling PB of data, and serves most analytical use cases. Other table engines exist for use cases such as CDC which need to support efficient updates.
The clause ORDER BY () means we have no index, and more specifically no order in our data. More on this later. For now, just know all queries will require a linear scan.
To confirm the table has been created:
SHOW CREATE TABLE posts
CREATE TABLE posts
(
`Id` Nullable(Int64),
`PostTypeId` Nullable(Int64),
`AcceptedAnswerId` Nullable(Int64),
`CreationDate` Nullable(DateTime64(3, 'UTC')),
`Score` Nullable(Int64),
`ViewCount` Nullable(Int64),
`Body` Nullable(String),
`OwnerUserId` Nullable(Int64),
`OwnerDisplayName` Nullable(String),
`LastEditorUserId` Nullable(Int64),
`LastEditorDisplayName` Nullable(String),
`LastEditDate` Nullable(DateTime64(3, 'UTC')),
`LastActivityDate` Nullable(DateTime64(3, 'UTC')),
`Title` Nullable(String),
`Tags` Nullable(String),
`AnswerCount` Nullable(Int64),
`CommentCount` Nullable(Int64),
`FavoriteCount` Nullable(Int64),
`ContentLicense` Nullable(String),
`ParentId` Nullable(String),
`CommunityOwnedDate` Nullable(DateTime64(3, 'UTC')),
`ClosedDate` Nullable(DateTime64(3, 'UTC'))
)
ENGINE = MergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')
ORDER BY tuple()
With our initial schema defined, we can populate the data using an INSERT INTO SELECT, reading the data using the s3 table function. The following loads the posts data in around 2 mins on an 8-core ClickHouse Cloud instance.
INSERT INTO posts SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 148.140 sec. Processed 59.82 million rows, 38.07 GB (403.80 thousand rows/s., 257.00 MB/s.)
The above query loads 60m rows. While small for ClickHouse, users with slower internet connections may wish to load a subset of data. This can be achieved by simply specifying the years they wish to load via a glob pattern e.g.
https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2008.parquetorhttps://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/{2008, 2009}.parquet. See here for how glob patterns can be used to target subsets of files.
Optimizing Types
One of the secrets to ClickHouse query performance is compression.
Less data on disk means less I/O and thus faster queries and inserts. The overhead of any compression algorithm with respect to CPU will in most cases be out weighted by the reduction in IO. Improving the compression of the data should therefore be the first focus when working on ensuring ClickHouse queries are fast.
For why ClickHouse compresses data so well, we recommend this article. In summary, as a column-oriented database, values will be written in column order. If these values are sorted, the same values will be adjacent to each other. Compression algorithms exploit contiguous patterns of data. On top of this, ClickHouse has codecs and granular data types which allow users to tune the compression techniques further.
Compression in ClickHouse will be impacted by 3 main factors: the ordering key, the data types, and any codecs used. All of these are configured through the schema.
The largest initial improvement in compression and query performance can be obtained through a simple process of type optimization. A few simple rules can be applied to optimize the schema:
- Use strict types - Our initial schema used Strings for many columns which are clearly numerics. Usage of the correct types will ensure the expected semantics when filtering and aggregating. The same applies to date types, which have been correctly provided in the Parquet files.
- Avoid Nullable Columns - By default the above columns have been assumed to be Null. The Nullable type allows queries to determine the difference between an empty and Null value. This creates a separate column of UInt8 type. This additional column has to be processed every time a user works with a nullable column. This leads to additional storage space used and almost always negatively affects query performance. Only use Nullable if there is a difference between the default empty value for a type and Null. For example, a value of 0 for empty values in the
ViewCountcolumn will likely be sufficient for most queries and not impact results. If empty values should be treated differently, they can often also be excluded from queries with a filter. Use the minimal precision for numeric types - ClickHouse has a number of numeric types designed for different numeric ranges and precision. Always aim to minimize the number of bits used to represent a column. As well as integers of different size e.g. Int16, ClickHouse offers unsigned variants whose minimum value is 0. These can allow fewer bits to be used for a column e.g. UInt16 has a maximum value of 65535, twice that of an Int16. Prefer these types over large unsigned variants if possible. - Minimal precision for date types - ClickHouse supports a number of date and datetime types. Date and Date32 can be used for storing pure dates, with the latter supporting a larger date range at the expense of more bits. DateTime and DateTime64 provide support for date times. DateTime is limited to second granularity and uses 32 bits. DateTime64, as the name suggests, uses 64 bits but provides support up to nanosecond granularity. As ever, choose the more coarse version acceptable for queries, minimizing the number of bits needed.
- Use LowCardinality - Numbers, strings, Date or DateTime columns with a low number of unique values can potentially be encoded using the LowCardinality type. This dictionary encodes values, reducing the size on disk. Consider this for columns with less than 10k unique values. FixedString for special cases - Strings which have a fixed length can be encoded with the FixedString type e.g. language and currency codes. This is efficient when data has the length of precisely N bytes. In all other cases, it is likely to reduce efficiency and LowCardinality is preferred.
- Enums for data validation - The Enum type can be used to efficiently encode enumerated types. Enums can either be 8 or 16 bits, depending on the number of unique values they are required to store. Consider using this if you need either the associated validation at insert time (undeclared values will be rejected) or wish to perform queries which exploit a natural ordering in the Enum values e.g. imagine a feedback column containing user responses
Enum(':(' = 1, ':|' = 2, ':)' = 3).
Tip: To find the range of all columns, and the number of distinct values, users can use the simple query
SELECT * APPLY min, * APPLY max, * APPLY uniq FROM table FORMAT Vertical. We recommend performing this over a smaller subset of the data as this can be expensive. This query requires numerics to be at least defined as such for an accurate result i.e. not a String.
By applying these simple rules to our posts table, we can identify an optimal type for each column:
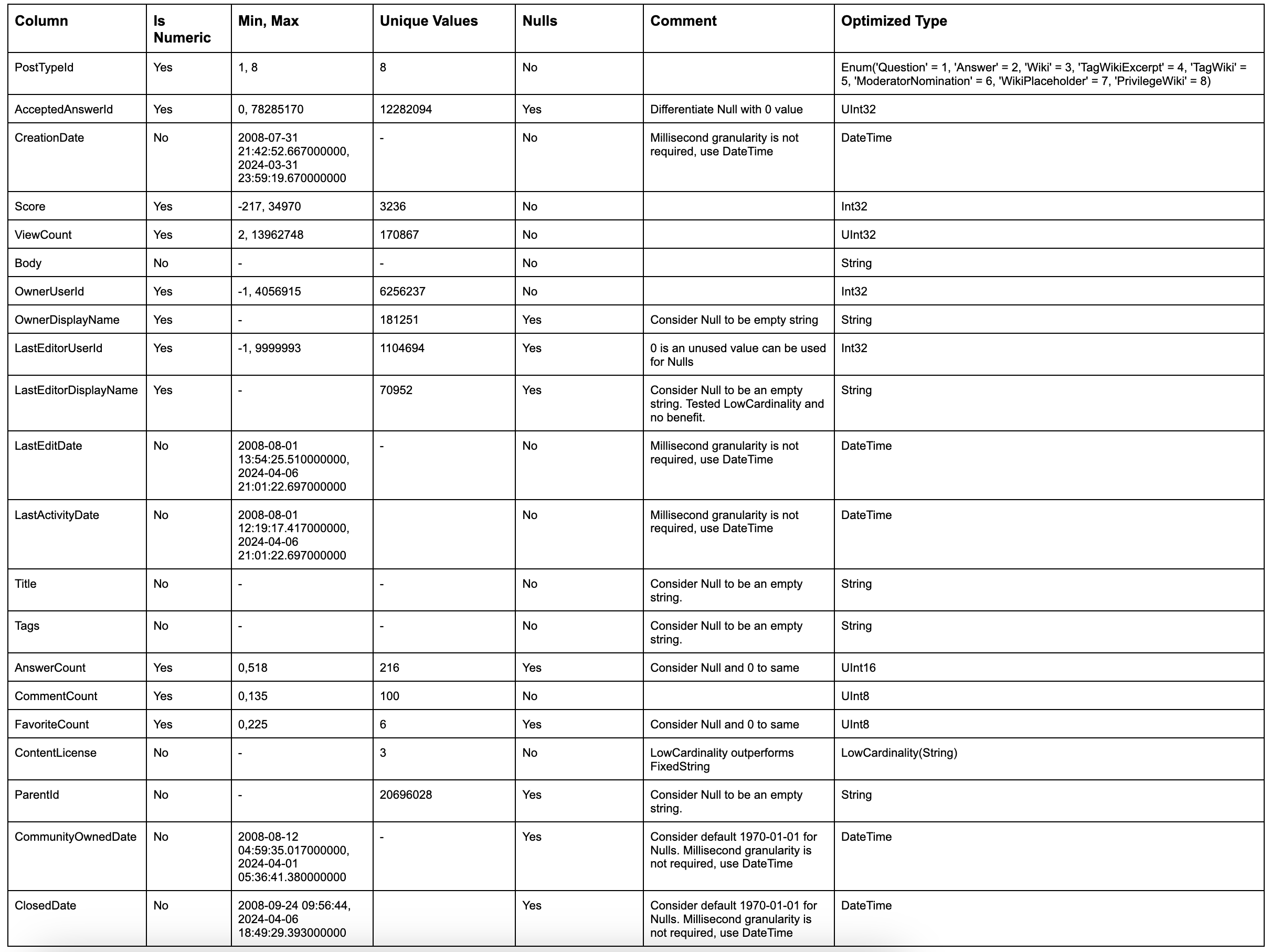
The above gives us the following schema:
CREATE TABLE posts_v2
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
COMMENT 'Optimized types'
We can populate this with a simple INSERT INTO SELECT, reading the data from our previous table and inserting into this one:
INSERT INTO posts_v2 SELECT * FROM posts
0 rows in set. Elapsed: 146.471 sec. Processed 59.82 million rows, 83.82 GB (408.40 thousand rows/s., 572.25 MB/s.)
We don't retain any nulls in our new schema. The above insert converts these implicitly to default values for their respective types - 0 for integers and an empty value for strings. ClickHouse also automatically converts any numerics to their target precision. Primary (Ordering) Keys in ClickHouse Users coming from OLTP databases often look for the equivalent concept in ClickHouse.
Choosing an ordering key
At the scale at which ClickHouse is often used, memory and disk efficiency are paramount. Data is written to ClickHouse tables in chunks known as parts, with rules applied for merging the parts in the background. In ClickHouse, each part has its own primary index. When parts are merged, then the merged part's primary indexes are also merged. The primary index for a part has one index entry per group of rows - this technique is called sparse indexing.
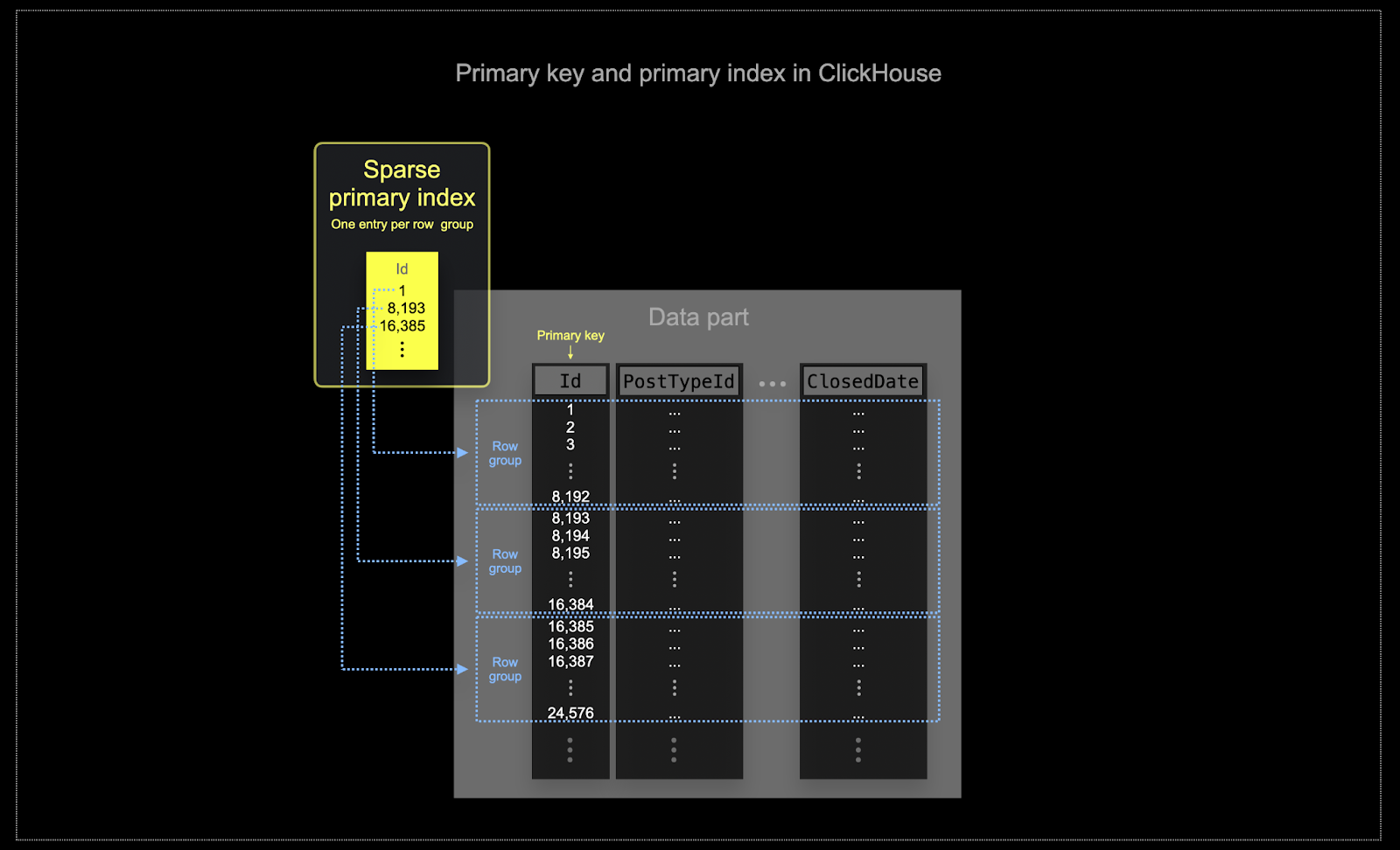
The selected key in ClickHouse will determine not only the index, but also order in which data is written on disk. Because of this, it can dramatically impact compression levels which can in turn affect query performance. An ordering key which causes the values of most columns to be written in contiguous order will allow the selected compression algorithm (and codecs) to compress the data more effectively.
All columns in a table will be sorted based on the value of the specified ordering key, regardless of whether they are included in the key itself. For instance, if
CreationDateis used as the key, the order of values in all other columns will correspond to the order of values in theCreationDatecolumn. Multiple ordering keys can be specified - this will order with the same semantics as anORDER BYclause in aSELECTquery.
Some simple rules can be applied to help choose an ordering key. The following can sometimes be in conflict, so consider these in order. Users can identify a number of keys from this process, with 4-5 typically sufficient:
- Select columns which align with your common filters. If a column is used frequently in
WHEREclauses, prioritize including these in your key over those which are used less frequently. Prefer columns which help exclude a large percentage of the total rows when filtered, thus reducing the amount of data which needs to be read. - Prefer columns which are likely to be highly correlated with other columns in the table. This will help ensure these values are also stored contiguously, improving compression.
GROUP BYandORDER BYoperations for columns in the ordering key can be made more memory efficient.
When identifying the subset of columns for the ordering key, declare the columns in a specific order. This order can significantly influence both the efficiency of the filtering on secondary key columns in queries, and the compression ratio for the table's data files. In general, it is best to order the keys in ascending order of cardinality. This should be balanced against the fact that filtering on columns that appear later in the ordering key will be less efficient than filtering on those that appear earlier in the tuple. Balance these behaviors and consider your access patterns (and most importantly test variants).
Example
Applying the above guidelines to our posts table, let's assume that our users wish to perform analytics which filter by date and post type e.g.:
"Which questions had the most comments in the last 3 months".
The query for this question using our earlier posts_v2 table with optimized types but no ordering key:
SELECT
Id,
Title,
CommentCount
FROM posts_v2
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
ORDER BY CommentCount DESC
LIMIT 3
┌───────Id─┬─Title─────────────────────────────────────────────────────────────┬─CommentCount─┐
│ 78203063 │ How to avoid default initialization of objects in std::vector? │ 74 │
│ 78183948 │ About memory barrier │ 52 │
│ 77900279 │ Speed Test for Buffer Alignment: IBM's PowerPC results vs. my CPU │ 49 │
└──────────┴───────────────────────────────────────────────────────────────────┴──────────────
10 rows in set. Elapsed: 0.070 sec. Processed 59.82 million rows, 569.21 MB (852.55 million rows/s., 8.11 GB/s.)
Peak memory usage: 429.38 MiB.
The query here is very fast even though all 60m rows have been linearly scanned - ClickHouse is just fast :) You’ll have to trust us ordering keys is worth it at TB and PB scale!
Lets select the columns PostTypeId and CreationDate as our ordering keys.
Maybe in our case, we expect users to always filter by PostTypeId. This has a cardinality of 8 and represents the logical choice for the first entry in our ordering key. Recognizing date granularity filtering is likely to be sufficient (it will still benefit datetime filters) so we use toDate(CreationDate) as the 2nd component of our key. This will also produce a smaller index as a date can be represented by 16, speeding up filtering. Our final key entry is the CommentCount to assist with finding the most commented posts (the final sort).
CREATE TABLE posts_v3
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
COMMENT 'Ordering Key'
--populate table from existing table
INSERT INTO posts_v3 SELECT * FROM posts_v2
0 rows in set. Elapsed: 158.074 sec. Processed 59.82 million rows, 76.21 GB (378.42 thousand rows/s., 482.14 MB/s.)
Peak memory usage: 6.41 GiB.
Our previous query improves the query response time by over 3x:
SELECT
Id,
Title,
CommentCount
FROM posts_v3
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
ORDER BY CommentCount DESC
LIMIT 3
10 rows in set. Elapsed: 0.020 sec. Processed 290.09 thousand rows, 21.03 MB (14.65 million rows/s., 1.06 GB/s.)
For users interested in the compression improvements achieved by using specific types and appropriate ordering keys, see Compression in ClickHouse. If users need to further improve compression we also recommend the section Choosing the right column compression codec.
Next: Data Modelling Techniques
Until now, we've migrated only a single table. While this has allowed us to introduce some core ClickHouse concepts, most schemas are unfortunately not this simple.
In the other guides listed below, we will explore a number of techniques to restructure our wider schema for optimal ClickHouse querying. Throughout this process we aim for Posts to remain our central table through which most analytical queries are performed. While other tables can still be queried in isolation, we assume most analytics want to be performed in the context of posts.
Through this section, we use optimized variants of our other tables. While we provide the schemas for these, for the sake of brevity we omit the decisions made. These are based on the rules described earlier and we leave inferring the decisions to the reader.
The following approaches all aim to minimize the need to use JOINs to optimize reads and improve query performance. While JOINs are fully supported in ClickHouse, we recommend they are used sparingly (2 to 3 tables in a JOIN query is fine) to achieve optimal performance.
ClickHouse has no notion of foreign keys. This does not prohibit joins but means referential integrity is left to the user to manage at an application level. In OLAP systems like ClickHouse, data integrity is often managed at the application level or during the data ingestion process rather than being enforced by the database itself where it incurs a significant overhead. This approach allows for more flexibility and faster data insertion. This aligns with ClickHouse’s focus on speed and scalability of read and insert queries with very large datasets.
In order to minimize the use of Joins at query time, users have several tools/approaches:
- Denormalizing data - Denormalize data by combining tables and using complex types for non 1:1 relationships. This often involves moving any joins from query time to insert time.
- Dictionaries - A ClickHouse specific feature for handling direct joins and key value lookups.
- Incremental Materialized Views - A ClickHouse feature for shifting the cost of a computation from query time to insert time, including the ability to incrementally compute aggregate values.
- Refreshable Materialized Views - Similar to materialized views used in other database products, this allows the results of a query to be periodically computed and the result cached.
We explore each of these approaches in each guide, highlighting when each is appropriate with an example showing how it can be applied to solving questions for the Stack Overflow dataset.